This post describes how to get started with a BO Semantic Layer SDK in Eclipse. It explains the steps to setup a project and provides an example of the code that imports, modifies and exports a UNX universe. You will also find instructions how to run JAR from command line.
BO Client Tools and SL SDK
You need to have SAP BusinessObjects BI platform 4.x Client Tools and it should include Semantic Layer SDK.
The Semantic Layer SDK is not included in default installation. You can check if you have it and enable it in Control Panel > Programs > Programs and Features > SAP BusinessObjects BI platform 4.x Client Tools > Uninstall/change > Modify.
Make sure that you have “Semantic Layer Java SDK”

This post assumes that the client tools are installed in the default location, namely in
C:\Program Files (x86)\SAP BusinessObjects
If your setup is different, update the paths accordingly.
Setup New Project with SL SDK
Create a new Project in Eclipse.
Right click on the project and select Build Path > Add External Archives.

Add Semantic layer SDK library sl_sdk.jar. It is located in:
C:\Program Files (x86)\SAP BusinessObjects\SAP BusinessObjects Enterprise XI 4.0\SL SDK\java

JRE
Make sure that the project is using 32 bit Java Runtime Environment. The best is to use Java from the BusinessObjects folder.
Right click on JRE System Library and select Properties.

Click Installed JREs and add new JRE by clicking on Add > Standard VM, and then providing the following path:
C:\Program Files (x86)\SAP BusinessObjects\SAP BusinessObjects Enterprise XI 4.0\win32_x86\jre

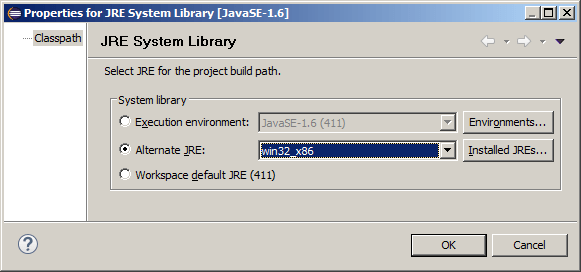
Select the created JRE:
The Program
Add class Program to the project and paste the following code:
import com.crystaldecisions.sdk.exception.SDKException; import com.crystaldecisions.sdk.framework.CrystalEnterprise; import com.crystaldecisions.sdk.framework.IEnterpriseSession; import com.crystaldecisions.sdk.framework.ISessionMgr; import com.sap.sl.sdk.authoring.cms.CmsResourceService; import com.sap.sl.sdk.authoring.businesslayer.*; import com.sap.sl.sdk.authoring.datafoundation.*; import com.sap.sl.sdk.authoring.local.LocalResourceService; import com.sap.sl.sdk.framework.SlContext; import com.sap.sl.sdk.framework.cms.CmsSessionService; public class Program { public static void main(String[] args) throws SDKException { String username = "Administrator"; String password = ""; String server = "localhost"; String auth = "secEnterprise"; String cmspath = "/Universes/webi universes"; String unxname = "eFashion.unx"; String tempFolder = "."; SlContext context = SlContext.create(); IEnterpriseSession enterpriseSession = null; try { System.out.println("Connecting"); ISessionMgr sessionMgr = CrystalEnterprise.getSessionMgr(); enterpriseSession = sessionMgr.logon(username, password, server, auth); CmsSessionService cmsSessionService = context.getService(CmsSessionService.class); cmsSessionService.setSession(enterpriseSession); CmsResourceService cmsService = context.getService(CmsResourceService.class); LocalResourceService localResourceService = context.getService(LocalResourceService.class); BusinessLayerFactory businessLayerFactory = context.getService(BusinessLayerFactory.class); DataFoundationFactory dataFoundationFactory = context.getService(DataFoundationFactory.class); System.out.println("Importing universe"); String blxPath = cmsService.retrieveUniverse(cmspath + "/" + unxname, tempFolder, true); System.out.println("Loading universe"); RelationalBusinessLayer businessLayer = (RelationalBusinessLayer) localResourceService.load(blxPath); String dfxPath = businessLayer.getDataFoundationPath(); DataFoundation dataFoundation = (DataFoundation) localResourceService.load(dfxPath); System.out.println("Modifying data foundation"); String sql = "select count(1) as Cnt from Shop_facts"; dataFoundationFactory.createDerivedTable("New_table", sql, dataFoundation); localResourceService.save(dataFoundation, dfxPath, true); System.out.println("Reloading data foundation"); businessLayer = (RelationalBusinessLayer) localResourceService.load(blxPath); System.out.println("Modifying business layer"); RootFolder rootFolder = businessLayer.getRootFolder(); Measure measure = businessLayerFactory.createBlItem(Measure.class, "New Measure", rootFolder); RelationalBinding binding = (RelationalBinding)measure.getBinding(); binding.setSelect("New_table.Cnt"); localResourceService.save(businessLayer, blxPath, true); System.out.println("Exporting universe"); cmsService.publish(blxPath, cmspath, true); } finally { if (context != null) { context.close(); } if (enterpriseSession != null) { enterpriseSession.logoff(); } System.out.println("Finished"); } } }
Run Configuration
Run the program. It will fail but a Run Configuration will be created.
Open the created run configuration in Run > Run Configurations
Add the following VM arguments
-Dbusinessobjects.connectivity.directory=”C:\Program Files (x86)\SAP BusinessObjects\SAP BusinessObjects Enterprise XI 4.0\dataAccess\connectionServer”
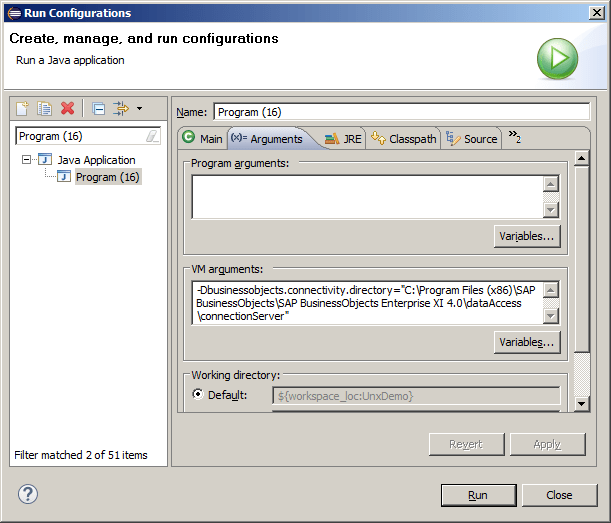
Add PATH variable with the value:
C:\Program Files (x86)\SAP BusinessObjects\SAP BusinessObjects Enterprise XI 4.0\win32_x86

Running the Code
The code uses eFashion.unx which should be located in webi universes. So you need to convert eFashion universe to eFashion.unx in Information Design Tool.
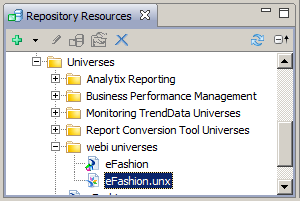
Now we are ready to run the program.
Click the button Run. The tool should execute without error and add table New_table and a measure New measure:
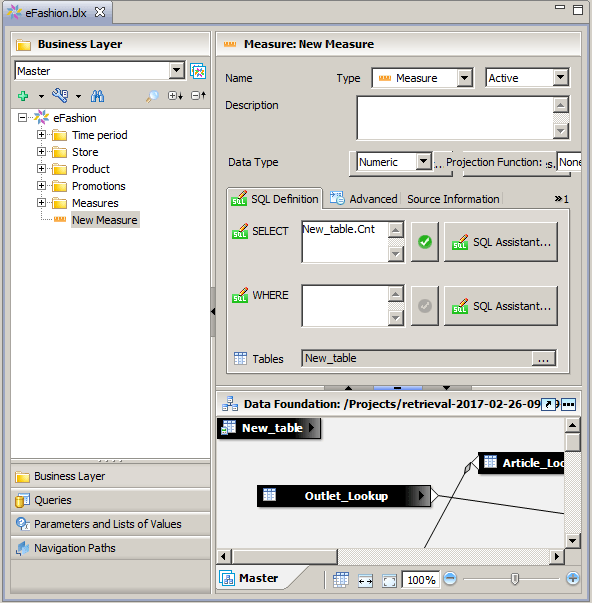
Running the Code from Command Line
Export the program to Executable JAR file (e.g. unxdemo.jar) from File > Export.
Create a batch file with the following script:
SET BO=C:\Program Files (x86)\SAP BusinessObjects\SAP BusinessObjects Enterprise XI 4.0
SET PATH=%BO%\win32_x86
SET JAVA=%BO%\win32_x86\jre
SET CD=%BO%\dataAccess\connectionServer
SET CP=unxdemo.jar;%BO%\SL SDK\java\sl_sdk.jar;%BO%\java\lib\*
“%JAVA%\bin\java.exe” -Dbusinessobjects.connectivity.directory=“%CD%“ -cp “%CP%“ Program
PAUSE
Run the batch: